|
|
Related Documentation:
The GEneral NEural SImulation System (GENESIS) is available in different ‘flavors’ that are shaped by the requirements of the user community. This community can be characterized by how the system is used. For example:
GENESIS was designed to allow the construction of biologically realistic models at many different levels, from subcellular components and biochemical reactions to complex models of single neurons, simulations of large networks, and systems-level models.
The design of the GENESIS simulator and interface is based on a“building block” approach. Simulations are constructed from modules that receive inputs, perform calculations on them, and then generate outputs. Model neurons are constructed from these basic components, such as dendritic compartments. and variable conductance ion channels. Compartments are linked to their channels and are then linked together to form multi-compartmental neurons of any desired level of complexity. Neurons may be linked together to form neural circuits. This modular component-based approach is central to the generality and flexibility of the system, as it allows modelers to easily exchange and reuse models or model components. In addition, it makes it possible to extend the functionality of GENESIS by adding new commands or simulation components to the simulator
The recent history of GENESIS has shown it to be increasingly difficult for developers from a wide range of scientific disciplines to contribute to simulator design and implementation. Although the old GENESIS scripting language interface (SLI) produced highly efficient modular object-oriented simulations that were easy to modify and extend, this was not the case with the source code which did not cleanly separate into its underlying components. It was difficult to add more modern Java-based graphical interfaces, alternate script parsers, and interfaces via the WWW. Such non-scalable architecture was not unique to GENESIS. The result is that experimentalists are often denied the opportunity to more easily ground empirical observation within the formalism of computational neuroscience.
In an effort to resolve the problems associated with a so-called “monolithic” software application, the CBI (Computational Biology Initiative) federated software architecture (see below for the meaning of “federated”) has been developed. We now introduce this architecture and give a brief overview of how GENESIS has been reconfigured on the basis of the CBI federated architecture design principles. This reconfiguration also involves a move from the imperative or procedural programming of the GENESIS Script Language Interpreter (SLI) to declarative programming. This has led to a new “look and feel” for GENESIS as simulations are now built by describing what should be done, rather than (as was the case with the SLI) describing in detail how to go about doing it. This has greatly simplified the creation and development of modeling projects and the running of simulations. Prior to describing the CBI architecture we illustrate some of the underlying design philosophy for a reconfigured GENESIS.
In software engineering, the process of breaking up a program into logical functions that minimize overlap is referred to as the “separation of concerns”. From this perspective, there are two fundamental considerations for software development:
On the basis of this type of analysis we have identified two principal concerns underlying the development of modeling software in the computational neurosciences: the separation between data and control, and the requirement for data-layering.
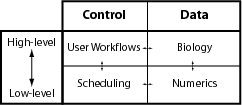
All software can be understood in terms of algorithms operating on input data to produce output data. For experimental research, the natural distinction between data and algorithms can be compared to the distinction between the biological system (data to be investigated) and the stimulation paradigm (tools supporting data investigation). For computational research (as illustrated in the figure below), the distinction between data and algorithms leads to a separation between model (data) and simulation control (control of data flows).
|
|
The complex multi-dimensional nature of a biological system distinguishes it from the mathematical representations and data formats employed by a computer-based model of the system. Specifically, it is the dynamical properties of a biological system that do not map easily to the logical principles and mathematical constructs used by software implementations.
In the figure above, the horizontally directed arrows indicate the location of software control interfaces, whereas, the vertical arrows indicate the location of the data flow interfaces. It is notable that if software includes diagonal interfaces between blocks, e.g. between Biology and scheduling or User workflows and numerics, the result will will be an application that can be classed as monolithic. With these considerations in mind we have developed a software architecture meta-framework that has been used as a guide in the reconfiguration of GENESIS.
The CBI federated software architecture provides a modular paradigm that places stand-alone software components into logical relationships. It is referred to as being “federated” as it extends the modular approach associated with the development of single applications to the functional integration of otherwise independent applications. In doing this the software architecture aims to provide a unified interface to diverse applications and mask from the user the differences, idiosyncracies, and implementations of the underlying applications and data sources.
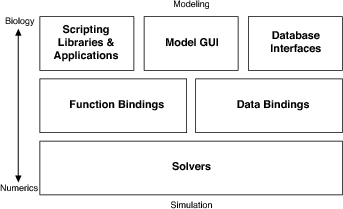
The Data/Control schema illustrated above was developed into a software architecture giving the components that form the building blocks of the CBI architecture (illustrated in the following figure).
Ideally, this architecture makes the underlying applications look to the user like a single system. This is achieved by recruiting different modules to provide the model building tools and simulator functionality required at the different stages of a project.
In summary, the CBI architecture provides a template for federated software development that, at its core, contains a CBI compliant simulator (the Model Container, Simulation Controller (SSP), Experimental Protocols (Experiment) and Solver (Heccer), located in the dashed box in the high level block diagram–above). It is the modularity of the architecture that simplifies connection to independent applications indirectly related to model construction and instantiation. In doing this it shares a number of ideas with the well-known three tier architectures paradigm (make link). The distinguishing feature of the CBI architecture is that the back-end comprises numerical solvers rather than relational databases.
The CBI compliant simulator indicated in the previous figure is expanded in the following figure to illustrate the key components. Data layers in the CBI architecture correspond to high-level data associated with biological concepts and extend to low level data such as numerical values employed by the solvers. The benefit of this layering of data is that it allows the mathematical and biological aspects of a model to be distinguished and separated by specific Data and Function bindings.
|
|
It is the clear delineation of the modules in the CBI architecture that allows both developers and users to choose to contribute to a single component with limited complexity, instead of being forced to contribute to the whole simulator and be exposed to tremendous complexity. Within the CBI paradigm each software component becomes self contained in the sense that it can be run independently. This has important advantages in that it facilitates the interoperability of software obtained from different sources by:
The CBI architecture provides three significant advantages for software development:
The recently developed CBI simulator architecture is an open framework that also provides a general context for ongoing GENESIS development. The architecture focuses users on the need to conceive, organize, execute and evaluate simulations, while allowing the development of new tools to support simulation based education, collaboration, and publication. The GENESIS modules that have been implemented, tested, and that are currently compliant with the CBI architecture include:
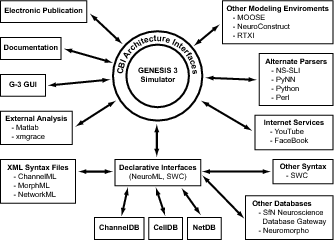
Using the CBI architecture, GENESIS is being developed with the necessary interfaces that will, in principle, allow any simulation system to use its features. The figure below shows the multiple external interfaces to GENESIS that are planned for the new architecture.